AIの「幻覚(ハルシネーション)」は避けられないと言われています。では、AIの性能とハルシネーションの発生率はどの様な関係があるのでしょうか? 性能が良いと言われるLLMほどハルシネーションの率は低い? 或いは性能を良く見せるためにハルシネーションの率は髙くなる? 本項では、米国および中国で開発されたLLMに焦点を当て、Chatbot Arena Leaderboardのスコアを性能指標、Vectara Hallucination Leaderboardのデータをハルシネーション率の指標として使用し大規模言語モデル(LLM)の性能とハルシネーション(誤情報生成)の発生率との間の相関関係を分析します。
2. 分析方法
2.1. データ収集
以下のデータソースから情報を収集しました。
- LLM性能データ: Chatbot Arena LLM Leaderboardから、各モデルのArenaスコア、開発組織、および国情報を取得しました。
- ハルシネーション率データ: Vectara Hallucination Leaderboardから、各モデルのハルシネーション率(要約の正確性に基づく)を取得しました。
2.2. データ処理
収集した2つのデータセットを、LLMのモデル名をキーとして結合しました。モデル名表記の揺れを吸収するため、部分一致や正規化処理を適宜行いました。性能スコア(Arena Score)とハルシネーション率は数値データとして扱いました。モデルの「Origin」(出身国)は、「Country」列の情報に基づき、「US」、「China」、「Other」に分類しました。
2.3. 相関分析
米国および中国のLLMに限定し、Arenaスコアとハルシネーション率の間のピアソンの相関係数を算出しました。
3. 分析結果
3.1. 相関分析結果
米国および中国のLLMにおけるArenaスコアとハルシネーション率の相関係数は以下の通りです。
Correlation between Arena Score and Hallucination Rate for US/China models: 0.07542770784422304
この相関係数は0に近く、現時点のデータセットにおいては、Arenaスコア(性能)とハルシネーション率の間に強い線形相関は見られないことを示唆しています。つまり、性能が高いモデルが必ずしもハルシネーションを起こしにくいわけではなく、またその逆も同様である可能性が考えられます。
3.2. データ概要(米国・中国モデル)
相関分析に使用した米国および中国のモデルのデータは以下の通りです。
| Model (Arena) | Organization | Country | Arena Score | Hallucination Rate (%) |
|---|---|---|---|---|
| Qwen2.5-Max | Alibaba | China | 1341.0 | 2.9 |
| DeepSeek-V3 | DeepSeek | China | 1318.0 | 3.9 |
| Claude 3.7 Sonnet (thinking-32k) | Anthropic | US | 1300.0 | 4.4 |
| Qwen2-72B-Instruct | Alibaba | China | 1187.0 | 4.7 |
| Snowflake Arctic Instruct | Snowflake | US | 1090.0 | 3.0 |
3.3. 散布図による可視化
以下の散布図は、横軸にChatbot Arenaスコア、縦軸にハルシネーション率を取り、米国(青)、中国(赤)、その他(緑)のLLMをプロットしたものです。
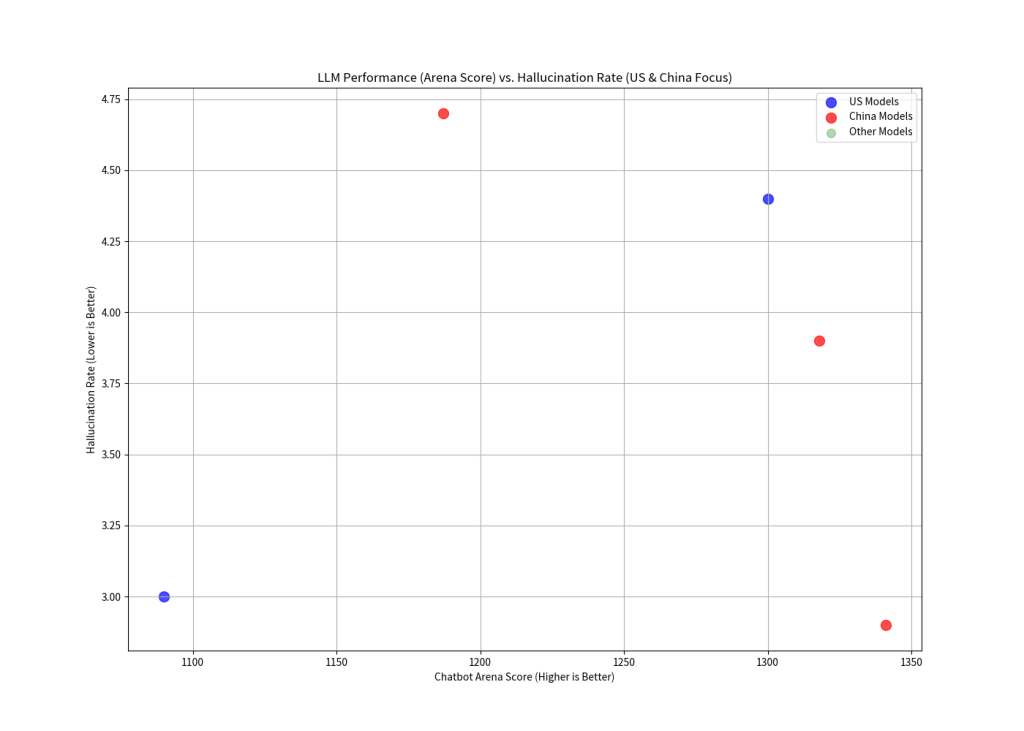
散布図からも、米国および中国のモデルにおいて、性能スコアとハルシネーション率の間に明確な傾向(右肩上がりや右肩下がり)は観察されにくいことが視覚的に確認できます。モデルはグラフ上に広範囲に分布しており、特定の相関パターンを読み取るのは困難です。
4. 考察と結論
本分析の結果、現時点で利用可能なデータに基づくと、LLMのChatbot Arenaにおける評価スコアと、Vectara Hallucination Leaderboardにおけるハルシネーション発生率の間には、特に米国および中国のモデルにおいて、強い線形相関は認められませんでした。相関係数は約0.075であり、これは非常に弱い正の相関を示唆しますが、統計的に有意な関連性があるとは言えません。
この結果は、LLMの一般的な対話性能と、事実に基づいた正確な情報を提供する能力(ハルシネーションの抑制)が、必ずしも比例しない可能性を示しています。高性能なモデルであってもハルシネーションを起こすリスクがあり、逆にスコアが中程度のモデルでもハルシネーション率が低い場合があることが考えられます。LLMを選定・評価する際には、総合的な性能だけでなく、ハルシネーション率のような特定の信頼性指標も個別に考慮することの重要性が示唆されます。
ただし、本分析は限られた数のモデルと特定の評価指標に基づいています。今後、より多くのモデルデータや多様な評価軸での分析を進めることで、さらに詳細な知見が得られる可能性があります。
5. 参考情報
- Chatbot Arena LLM Leaderboard: https://huggingface.co/spaces/lmarena-ai/chatbot-arena-leaderboard
- Hallucination Leaderboard by Vectara: https://github.com/vectara/hallucination-leaderboard
※本分析は、Manusを利用して作成しました。